- ChatGPT、TikTok、Temu打不开,专用网络美国海外专线光纤:老张渠道八折优惠。立即试用>
- GPT3.5普通账号:美国 IP,手工注册,独享,新手入门必备,立即购买>
- GPT-4 Plus 代充升级:正规充值,包售后联系微信:laozhangdaichong7。下单后交付>
- OpenAI API Key 独享需求:gpt-4o、claude API、gemini API不限量供应。立即购买>
- OpenAI API Key 免费试用:搜索微信公众号:紫霞街老张,输入关键词『试用KEY』
本店稳定经营一年,价格低、服务好,售后无忧,下单后立即获得账号,自助下单 24小时发货。加V:laozhangdaichong7
立即购买 ChatGPT 成品号/OpenAI API Key>>
请点击,自助下单,即时自动发卡↑↑↑
什么是快手直播间数据抓取
快手直播间数据抓取是指通过编写Python爬虫脚本,从快手直播平台上抓取直播间的相关数据信息,如视频、评论、弹幕、用户数据等。
快手是中国流行的视频分享社交平台之一,拥有大量的直播间内容。通过抓取这些数据,可以进行数据分析、个性化推荐、用户画像分析等应用。
快手直播间数据抓取的意义
快手直播间数据抓取在如今的大数据时代具有重要意义。通过抓取快手直播间的数据,可以对用户喜好进行分析,从而进行个性化推荐。此外,还可以对快手直播间的内容进行监控和分析,了解用户需求和流行趋势,做出相应的调整和优化。同时,快手直播间数据抓取也有助于进行用户画像分析,了解用户的特征和行为习惯,从而制定精准的运营策略。总之,通过快手直播间数据抓取,可以为快手平台提供更好的用户体验和增加用户粘性。
快手直播间数据抓取的具体步骤
下面是进行快手直播间数据抓取的具体步骤:
- 编写Python爬虫脚本,用于模拟请求并获取快手直播间页面数据。
- 分析快手直播间页面的HTML结构,确定需要抓取的数据信息。
- 使用正则表达式或XPath等方法,提取所需的数据。
- 将抓取到的数据存储到数据库或文件中,方便后续的数据分析和处理。
快手直播间数据抓取的注意事项
在进行快手直播间数据抓取时,需要注意以下几点:
- 尊重平台规定和用户隐私,遵守相关法律法规。
- 避免对快手服务器造成过大的负载压力,合理控制抓取频率和数据量。
- 注意数据的及时性和准确性,及时更新抓取脚本以适应平台接口的更新。
- 合理使用数据,遵守数据使用规范并保护用户隐私。
快手直播间数据抓取的应用场景
快手直播间数据抓取可以应用于以下场景:
- 数据分析:通过对快手直播间数据进行深入分析,了解用户需求和行为习惯,为产品优化和运营决策提供参考。
- 个性化推荐:根据用户的历史行为和兴趣偏好,进行个性化推荐,提供更好的用户体验。
- 用户画像分析:通过对用户的数据进行挖掘和分析,了解用户的特征和行为习惯,制定精准的用户运营策略。
- 舆情监测:通过对快手直播间的数据进行监控和分析,了解用户反馈和意见,及时处理和回应。
参考链接:

快手直播间数据抓取的主要步骤
快手直播间数据抓取是一项常见且重要的任务,通过抓取直播间数据可以获取热门直播间的信息,并进行大数据分析。以下是实现快手直播间数据抓取的主要步骤:
- 确定目标数据:首先需要确定要抓取的目标数据,例如直播间的礼物、弹幕、观众数量等。
- 通过开发者工具分析网络请求:使用浏览器的开发者工具,分析快手客户端与服务器之间的网络请求,了解数据请求的接口和参数。
- 编写爬虫脚本:根据分析得到的网络请求接口和参数,使用Python等编程语言编写爬虫脚本,模拟发送请求获取目标数据。
- 存储数据:将抓取的数据保存到数据库或文件中,以备后续分析和使用。
通过开发者工具分析网络请求
为了抓取快手直播间的数据,我们需要分析快手客户端与服务器之间的网络请求。通过浏览器的开发者工具,我们可以查看网络请求的详细信息,包括请求的接口、参数、请求方法等。具体的步骤如下:
- 打开快手客户端,并进入目标直播间。
- 打开浏览器的开发者工具。在Chrome浏览器中,可以通过右键点击页面,选择“检查”或“检查元素”,然后切换到“Network”选项卡。
- 在开发者工具中,刷新直播间页面,观察网络请求的情况。找到与直播间相关的请求,查看其详细信息。
- 分析请求的接口、参数和返回数据,了解如何向服务器发送请求获取目标数据。
通过以上步骤,我们可以研究出如何向快手服务器发送请求获取直播间的目标数据。
编写爬虫脚本
在了解了网络请求的接口和参数后,我们可以使用Python等编程语言编写爬虫脚本,模拟发送请求获取直播间数据。具体的步骤如下:
- 导入必要的库,例如requests、bs4等。
- 构造请求头和请求体,指定请求的接口和参数。
- 发送HTTP请求,获取服务器返回的数据。
- 解析服务器返回的数据,提取目标数据并进行存储。
编写好爬虫脚本后,我们可以运行脚本,即可自动抓取快手直播间的数据。
存储数据
抓取的直播间数据可以选择存储到数据库或文件中,以便后续分析和使用。常用的存储方式有:
- 数据库:可以使用MySQL、MongoDB等数据库管理系统,将抓取的数据存储到数据库表中。
- 文件:可以将数据保存为CSV、Excel等文件格式,方便后续处理和分析。
根据具体的需求和数据量大小,选择适合的存储方式。

确定目标数据
在进行快手直播间数据抓取前,首先需要确定要抓取的目标数据,例如视频、评论、弹幕等。根据需要进行数据筛选和过滤,确定要抓取的具体内容。
快手直播间的数据种类丰富,可以根据需求选择抓取的数据类型,例如直播视频、粉丝评论、主播信息等。
在进行数据抓取之前,需要明确抓取的目标数据类型,这样才能有针对性地进行抓取和处理。根据需求,可以选择抓取直播视频、粉丝评论、主播信息等。同时,还可以根据时间、主题、地域等进行数据筛选和过滤,以获取更加具体和准确的数据。
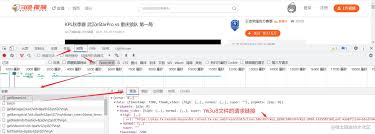
通过开发者工具分析网络请求
为了抓取快手直播间的数据,可以利用开发者工具进行网络请求的分析。通过抓包工具获取网络请求的URL、参数和返回数据等信息,以便编写爬虫脚本。
开发者工具可以打开浏览器的开发者模式,在网络选项卡下查看请求详情,包括请求头、请求体等信息。通过分析这些请求,可以确定需要爬取的数据。
步骤一:打开开发者工具
首先,打开快手直播间的网页版,并按下F12键,打开开发者模式。然后,在开发者工具中切换到网络选项卡,可以看到所有的请求信息。
步骤二:分析网络请求
在网络选项卡中,可以查看所有的请求信息。通过观察请求URL、请求参数和返回数据,可以确定需要爬取的数据。
- 请求URL:请求URL是请求数据的地址,包含了数据来源的网址。可以通过分析URL的规律,找出需要爬取的数据的URL。
- 请求参数:请求参数是发送给服务器的数据,可以通过分析参数的内容和格式,确定如何构造请求。
- 返回数据:返回数据是服务器返回的响应,包含了需要爬取的数据。可以通过观察返回数据的结构和字段,确定如何提取所需的数据。
步骤三:编写爬虫脚本
根据分析的网络请求信息,编写爬虫脚本来获取所需的数据。
首先,使用网络请求库发送HTTP请求,将请求URL和请求参数作为参数传入。然后,解析返回的数据,提取所需的数据字段。
可以使用Python的第三方库,如Requests和BeautifulSoup来发送HTTP请求和解析HTML。
注意事项:
在进行网络请求分析时,需要注意以下几点:
- 保持请求频率适度:如果请求频率过高,易被服务器封禁IP。
- 模拟浏览器行为:可以在网络请求头中设置User-Agent字段,来模拟浏览器的访问。
- 处理反爬机制:一些网站可能会有反爬机制,如验证码等。需要针对具体情况进行处理。
通过开发者工具分析网络请求可以帮助我们确定获取数据的来源和编写爬虫脚本的方式。了解网络请求的URL、参数和返回数据等信息,有助于我们更好地抓取所需的数据。
编写爬虫脚本
编写爬虫脚本是获取快手直播间数据的关键步骤。以下是编写爬虫脚本的一般步骤:
- 确定目标数据:在开始编写脚本之前,需要确定要抓取的数据类型,例如直播间的观众数量、点赞数、弹幕等。
- 分析网络请求:查看快手直播间的网络请求,了解数据是如何通过HTTP请求返回的。
- 导入相应的库和工具:使用Python编程语言,导入相应的爬虫框架或库,如Requests、Scrapy等。
- 发送HTTP请求:通过编写代码,发送HTTP请求,获取快手直播间的数据。
- 解析返回的数据:使用相应的解析库,如BeautifulSoup、XPath等,解析返回的页面数据,提取所需的信息。
- 数据清洗和处理:对解析到的数据进行清洗和处理,以确保数据的准确性和一致性。
- 持久化数据:将清洗和处理后的数据保存到数据库或文件中,以便后续分析和使用。
编写爬虫脚本时需要注意一些常见的问题和技巧:
- 登录认证:如果需要登录才能获取到目标数据,可以使用相应的登录认证方法,如使用Cookie、Session等。
- 限制IP访问:一些网站可能对爬虫行为进行限制,可以设置延时、使用代理IP等方式缓解被封IP的风险。
- 数据解析:根据目标数据的格式和结构,选择合适的解析方法,如正则表达式、CSS选择器、XPath等。
- 数据清洗:对解析到的数据进行清洗,去除不需要的标签、空格、换行符等,保留有效的数据。
- 异常处理:网络请求可能会遇到各种异常,如超时、连接失败等,需要进行相应的异常处理,确保脚本的稳定性。

存储数据
在完成数据抓取后,需要将获取到的数据进行存储。可以选择合适的数据库或文件格式,将数据保存下来。
常用的数据存储方式包括使用关系型数据库,如MySQL、SQLite等,或者使用非关系型数据库,如MongoDB等。也可以将数据保存为文件,如CSV、JSON等格式。
存储数据时要注意数据结构的规范性和完整性,以便后续的数据分析和应用。
关系型数据库
关系型数据库是一种使用表格结构来存储和组织数据的数据库。它使用结构化查询语言(SQL)进行数据操作和管理。常用的关系型数据库包括MySQL、SQLite、Oracle等。
关系型数据库适用于需要保持数据一致性和完整性的场景,可以使用事务来保证数据的原子性、一致性、隔离性和持久性。关系型数据库支持复杂的查询和数据关联操作,方便进行数据分析和统计。
非关系型数据库
非关系型数据库是一种使用键值对、文档、列族等非结构化方式存储和组织数据的数据库。它不需要固定的模式和表结构,可以根据需要动态添加字段和数据。常用的非关系型数据库包括MongoDB、Redis、Cassandra等。
非关系型数据库适用于需要处理大量的非结构化或半结构化数据的场景,具有高性能、可伸缩性和灵活性的特点。非关系型数据库可以更好地支持分布式计算和存储,适用于大数据应用和实时数据分析。
文件格式
如果数据量较小或不需要复杂的查询和关联操作,可以将数据保存为文件格式。常用的文件格式包括CSV(逗号分隔值)和JSON(JavaScript对象表示法)。
CSV格式是一种用逗号或其他分隔符分隔字段值的文本文件,适用于简单的表格数据。可以使用文本编辑器或电子表格软件打开和编辑CSV文件。
JSON格式是一种轻量级的数据交换格式,具有良好的可读性和可扩展性。可以使用文本编辑器或各种编程语言读取和写入JSON文件。
数据结构的规范性和完整性
无论选择哪种数据存储方式,都需要注意数据结构的规范性和完整性。数据结构规范性指的是数据字段和类型的定义是否一致,方便数据的查询和分析。数据结构完整性指的是数据的完整性和一致性,确保数据没有丢失或冗余。
在设计数据结构时,可以使用数据库的模式或架构来定义表和字段的结构。同时,可以使用约束条件或校验规则来保证数据的有效性和一致性,如唯一约束、外键约束、数据验证规则等。
总之,存储数据是数据采集过程中的重要一环。选择合适的数据库或文件格式,并根据需要设计和优化数据结构,可以确保数据的有效性和可用性,方便后续的数据分析和应用。

快手直播爬虫的常见问答Q&A
问题:
Python如何爬取快手直播间数据?
答案:
要使用Python爬取快手直播间数据,可以按照以下步骤进行:
- 使用Python的requests库发送HTTP请求,模拟访问快手直播间的网页。
- 解析返回的HTML页面,使用Python的BeautifulSoup库提取所需的数据。
- 根据需要,可以使用正则表达式进行进一步的数据提取和处理。
- 将提取的数据保存到本地文件或数据库中,进行后续分析和使用。
以下是一个简单的示例代码:
import requests
from bs4 import BeautifulSoup
# 发送请求,获取快手直播间的网页内容
url = "https://www.kuaishou.com/live/<直播间ID>"
response = requests.get(url)
html = response.text
# 解析HTML页面
soup = BeautifulSoup(html, "html.parser")
# 提取所需的数据
# ...
需要注意的是,爬取快手直播间数据需要遵循相关的法律法规和平台的规定,确保合法、合规。