- ChatGPT、TikTok、Temu打不开,专用网络美国海外专线光纤:老张渠道八折优惠。立即试用>
- GPT3.5普通账号:美国 IP,手工注册,独享,新手入门必备,立即购买>
- GPT-4 Plus 代充升级:正规充值,包售后联系微信:laozhangdaichong7。下单后交付>
- OpenAI API Key 独享需求:gpt-4o、claude API、gemini API不限量供应。立即购买>
- OpenAI API Key 免费试用:搜索微信公众号:紫霞街老张,输入关键词『试用KEY』
立即购买 ChatGPT 成品号/OpenAI API Key>> 请点击,自助下单,即时自动发卡↑↑↑
详细指南:如何训练并利用ChatGPT模型实现个性化应用
想要了解如何训练并利用ChatGPT模型实现个性化应用?这篇详细指南将引导您如何训练自己的ChatGPT、ChatGPT4模型,并利用现有数据与模型进行训练,生成您独有的模型。详尽的步骤包括数据集准备、训练配置及高级应用方法,例如如何训练ChatGPT来写文章、小说等内容,帮助您充分利用ChatGPT的强大功能,创建个性化的AI解决方案。
说在前面
在如今的数字化时代,人工智能(AI)已成为不可或缺的技术之一。其中,ChatGPT是一种广受欢迎的语言模型,被广泛应用于对话机器人、内容生成等领域。但是,如何训练和利用ChatGPT模型实现个性化应用,仍然是许多人关心的问题。本篇文章将为您详细解答这一问题,您将学会如何从零开始训练一个属于自己的ChatGPT模型,并利用它进行个性化应用。
重要性说明:定制化的ChatGPT模型可以更好地满足特定需求,无论是写文章、小说,还是用于客户服务、教育等场景,都能显著提升效率和效果。
预期内容概述:本文将涵盖从ChatGPT的基本概念,到数据集准备、训练配置、模型训练、应用方法等,各个环节全面讲解。
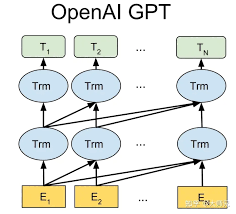
ChatGPT:背景介绍
定义和基本概念:ChatGPT是基于GPT(Generative Pre-trained Transformer)架构的语言模型,由OpenAI开发。它通过大量的文本数据进行预训练,具备生成自然语言文本的能力。
历史和发展:GPT的推出标志着自然语言处理(NLP)的重要里程碑。随着GPT-2、GPT-3及最新的GPT-4的发布,其生成文本的能力、性能和应用领域都得到了显著提升。
如何训练自己的ChatGPT模型
数据准备
正确的数据准备是训练成功的关键。您需要收集大量的高质量文本数据,且数据需要与预期应用高度相关。以下是数据准备的步骤:
- 数据收集:收集您感兴趣领域的文本数据,如对话日志、文章或小说。
- 数据清洗:去除无效数据、纠正错误,并确保数据格式统一。
- 数据标注:根据需求标注数据,例如对话数据可以标注说话人角色、情绪等。
训练配置
训练ChatGPT模型需要进行模型和训练参数的配置:
- 选择模型:根据需求选择合适版本的GPT模型(如GPT-3、GPT-4)。
- 硬件配置:准备强大的计算资源,如高性能GPU服务器。
- 训练参数:设置学习率、批处理大小、训练步数等参数。
模型训练
在数据和配置准备就绪后,即可开始训练模型。以下是详细步骤:
- 数据加载:使用特定的框架(如PyTorch、TensorFlow)加载数据集。
- 模型初始化:加载预训练的GPT模型并进行微调。
- 训练过程:通过反向传播算法不断优化模型参数。
- 模型保存:训练完成后,将模型保存为文件,方便后续加载和使用。
高级应用方法
训练好的ChatGPT模型可以用于多种高级应用。以下是几种常见应用场景:
- 写文章:利用ChatGPT生成的自然语言文本,可以辅助写作并提高创作效率。
- 写小说:通过提供角色和故事背景,让ChatGPT生成具有连贯性的小说章节。
- 客户服务:将训练好的模型嵌入到客户服务系统,实现智能对话和问题解答。
训练ChatGPT的实用Tips
- 多样化的数据:使用多种类型和风格的数据进行训练,提升模型的多样性和鲁棒性。
- 定期评估性能:定期使用验证集评估模型性能,并根据结果进行适当调整和优化。
- 不断更新数据:定期添加新的数据,保持模型与时俱进。
- 使用小批量训练:在资源允许的情况下,使用小批量数据进行训练,效率更高。
- 避免过拟合:在训练过程中监控并防止模型过拟合,确保泛化能力。
常见问题解答(FAQ)
- Q:训练ChatGPT需要多少数据?
A:具体数量因应用而异,但通常需要数百万到数亿字的文本数据。 - Q:需要什么硬件和软件环境?
A:高性能GPU、充足的存储空间,并且需要安装深度学习框架(如PyTorch、TensorFlow)。 - Q:能否基于预训练模型进行微调?
A:当然可以,微调可以大大减少训练时间和资源。 - Q:数据隐私如何保障?
A:确保所有训练数据均已脱敏,且遵循相关隐私法规和标准。 - Q:如何评估训练效果?
A:通过验证集测试模型生成的文本的流畅性、相关性和准确性。
总结
训练和利用ChatGPT模型实现个性化应用是一个复杂但值得投资的过程。通过本文,您了解到从数据收集、训练配置到模型训练和应用的详细步骤。定制化的ChatGPT模型能够在写作、小说创作、客户服务等多个领域显著提升效率和效果。希望您能按照本文提供的步骤,创建出自己理想的个性化ChatGPT模型。下一步,您可以开始收集数据,并按照优化的训练步骤进行实践,为实现个性化的AI应用迈出坚实的一步。